

Notifications
Present notifications effectively on OHMD to minimize distractions to primary tasks (e.g. notification display for conversational settings)

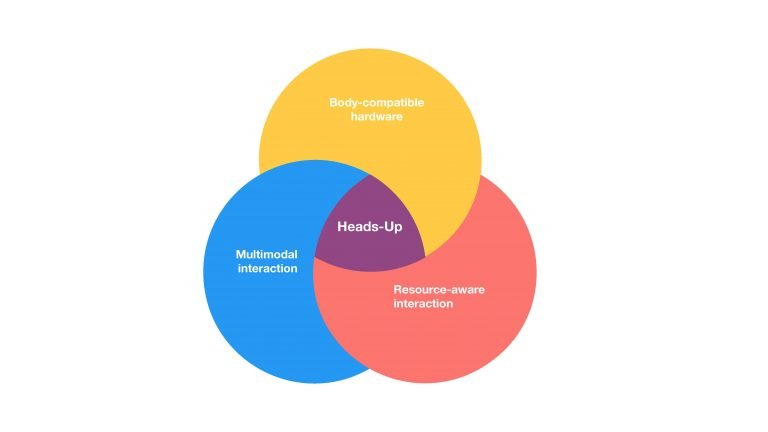
Resource interaction model
Establish how different situations affect our ability to in-take information on different input channels. Understand what input methods are comfortable and non-intrusive to users’ everyday tasks.

Monitoring Attention
Monitor attention state fluctuations continuously and reliably via EEGs (e.g. during video-learning scenarios)

Education & Learning
Design learning videos on OHMD for on-the-go situations, effectively distributing users’ attention between learning and walking tasks. Support microlearning in mobile scenarios (mobile information acquisition).

Healthcare & Wellness
Facilitate OHMD-based mindfulness practice that is highly accessible, convenient, and easy for novice practitioners to implement in casual everyday settings

Text Presentation
Explore text display design factors for optimal information consumption on OHMDs (e.g. in mobile environments)

Developer/Research tools for Heads-Up applications
Provide testing and development tools to help researchers and developers build Heads-Up applications, streamlining their work process (e.g. learning video-builder)











